Table of Contents
Recording and Managing Data – Automation In Biostratigraphy
The sheer volume of data generated by biostratigraphers is extensive. Either generated academically or commercially, the data are stored digitally within numerous software platforms ranging from the simple spreadsheet to complex bespoke databases which include tools for well- or section- management, correlation, chart production and data analysis. There are also extensive web-based facilities which contain useful information on fossil classification and distribution (see list of sources at the end of this manual).

The digital storage of biostratigraphical data only “got going” in the late 1980’s. The key database software, StrataBugs, came out of BP in the 1990’s. It is used by almost all Biostrat consultancies and many E&P companies that have biostratigraphers. RagWare & BugWare are primarily used by US based biostratigraphy consultancies. Biostratigraphical data interpretation software used in the industry stem from the Technical Alliance for Computation Stratigraphy (TACS) project run at EGI, Utah by Tony Gary.
Academics (in the loose sense) tend to be interested in the classification and evolutionary history of a particular set or subset of organisms and their biology/paleobiology and ecology. Commercial workers tend to be more interested in the stratigraphic limits of individual species or genera and their paleoenvironmental significance because of the value of this kind of data to exploration & production issues. The two are not mutually exclusive but there can be apparent disagreements – especially among industrial workers – on taking a strict “academic” approach over a “pragmatic” one. Consequently, different tools have evolved for different purposes but both can be very useful.
The recording of raw biostratigraphic data is relatively simple, being – for an individual well or section – a more-or-less simple plot of fossil occurrence(s) against sample position relative to a fixed datum. In commercial applications this is almost exclusively well-data with a 2D matrix of different fossil species plotted against the depth(s) in the well or section they have been recorded. The relative or absolute abundances of each species in each sample can also be recorded. With the addition of more and more wells, the data begins to occupy a 3-dimenstional volume of data-space.
At such a point it becomes essential to make sure the fossil taxonomic units (i.e. “species”) one is using is universally consistent across the whole 3D volume. This is particularly important in dealing with correlations between wells that are not only some distance apart in space, but that were also analysed biostratigraphically with a significant time-difference between them, and by different scientists. The discussion on fossil taxonomy (how organisms are classified and named) below shows that achieving such consistency can be difficult as fossil names can and do change over time as our overall knowledge of a fossil species or group improves. A stratigraphically-useful species recorded in an older well, and the same species (recorded under a different name) in a newer well may not be readily identified as the same by a non-specialist and therefore a potentially useful correlation line is missed. It becomes even more difficult when, for example, an operating company is dealing with data generated by a number of different biostratigraphic subcontractors each of whom may use different systems of fossil naming as well as coping with name changes over time.
These changes tend to originate on the “academic” side of the science and enter the “commercial” sphere sooner or later as they are adopted, rather piecemeal, by understandably conservative operators and commercial contractors. Some operators and contractors are known to use naming conventions which were set up perhaps half a century ago and are, by now, surpassed by more up-to-date “academic” systems. However, such antiquated commercial systems provide necessary stability and consistency over the lifetime of a productive field or even a complete basin. Some web-based sources which compile up-to-date more “academic” taxonomic thinking across several important microfossil groups are given at the end of this manual.
A good piece of biostratigraphic databasing software will have the capability to record the progression of such changes in the form of a so-called “Species Dictionary” which acts as a central repository for both present and historical naming conventions, together with current biostratigraphic range and paleoenvironmental information for individual taxa. In this way, valuable but historical “out of date” data can be used with equivalent value to more recently generated data based on “current thinking”. Data from “old” wells can be redisplayed using up-to-date naming conventions which assists both correlation and paleoenvironmental determination.
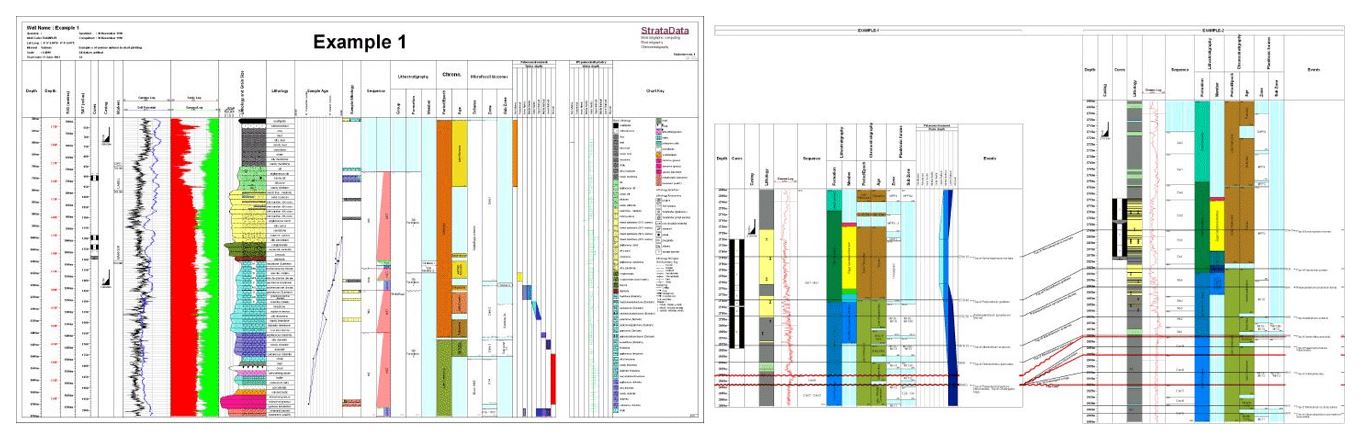 An example data distribution chart and correlation panel, in this case generated by the “StrataBugs”© program (figures from the StrataData Ltd. website (http://www.stratadata.co.uk/sbugs_examplecharts.shtml?sbugs=true)
An example data distribution chart and correlation panel, in this case generated by the “StrataBugs”© program (figures from the StrataData Ltd. website (http://www.stratadata.co.uk/sbugs_examplecharts.shtml?sbugs=true)
Achieving taxonomic consistency in datasets is also a prerequisite to the development of automation in biostratigraphy, with age-determination, paleoenvironmental analysis and multiwell correlation all possible with current computing capabilities. As long, of course, as the data attributes (the names/taxonomy and the biostratigraphic and environmental limits) are correctly assigned and consistently applied.
Data sets held by operating companies can be huge. The data may already have been interpreted “on paper” and indeed, data could potentially be re-interpreted (by a “thinking biostratigrapher”) at any future point. However, with more volumes of data becoming available and fewer and fewer biostratigraphers available to work with the data, the need for automation in biostratigraphic interpretation becomes clear. One promising approach towards automation in biostratigraphy would be to combine a “species dictionary” which deals with taxonomic issues, synonyms, an agreed geological age-range for individual species and genera and environmental descriptors, with an “occurrences database” where sequenced biostratigraphic data is stored in a geospacially-enabled, palinspastically-reconstructed virtual volume.
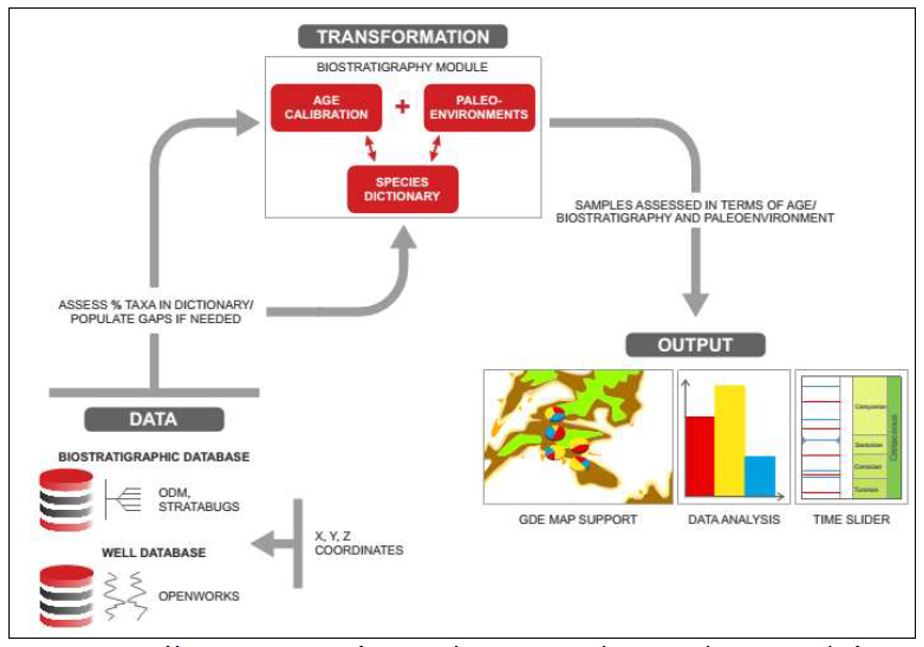 A possible route to automation in biostratigraphy using a “species dictionary” and an occurrence database.
A possible route to automation in biostratigraphy using a “species dictionary” and an occurrence database.